概要
Anchor的设计是现今大多数目标检测框架的基础,高性能的目标检测框架通常依赖于密集的Anchors的设计,这些Anchors基于预定义的尺度与长宽比。 本文提出了GA-RPN利用图像的语义信息指导Anchor的生成,联合两条支路,一路预测物体的中心点位置,另外一路预测对应位置的尺度和长宽比。此外为了保持特征的一致性,采用了一个Feature adaption module。
方法
Anchor的设计遵循着两个原则:
alignment
to use convolutional features as anchor representations, anchor centers need to be well aligned with feature map pixels.
consistency
the receptive field and semantic scope are consistent in different regions of a feature map, so the scale and shape of anchors across different locations should be consistent.
论文主要围绕着这个公式展开:
该公式主要抓住了两个重要的直觉,(1) 物体可能只存在一张图像的某些区域;(2) 物体的形状,尺度,比例和它的位置有关。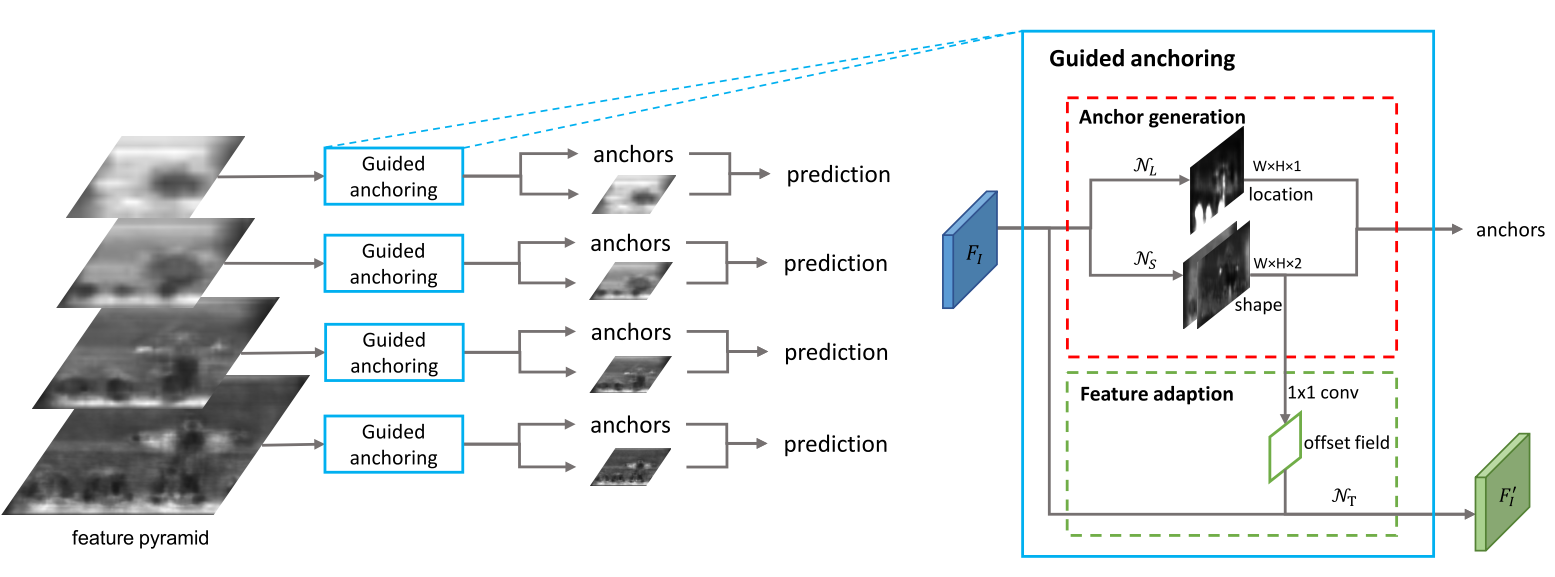
该网络主要分为三个部分,Anchor Location Prediction, Anchor Shape Prediction, Anchor-Guided Feature Adaption, 以下将对这三个部分分别介绍。
Anchor Location Prediction
对于特征图$F_I$而言,该分支主要预测对应的位置上物体存在的概率$p(i,j|F_I)$其中$i,j$表示在特征图上的位置,对应的在原始图片的位置为为$((i+\frac{1}{2})s,(j+\frac{1}{2})s)$,其中s是特征图上的步进长度。该分支$N_L$使用一个$1\times1$的卷积层,然后通过sigmoid函数将卷积后的结果转为概率。基于上述产生的概率图,然后设定一个阈值$\epsilon_L$滤除大约$90%$的regions。由于大部分区域并不包含物体,因此使用masked convolution替代后续的卷积层。
Anchor Shape Prediction
确定物体的可能位置后,下一步就是预测物体的形状。基于特征图$F_I$该分支预测对应位置上$(w,h)$,然而直接预测这两个值,难度较大,因此通过预测$dw$和$dh$,然后通过如下公式映射到对应的$w$和$h$:
其中$s$是特征图上的步进长度,$\sigma$是缩放因子(该超参数设置为8),该分支$N_S$同样由一个$1\times1$的卷积层组成,然后产生一个两通道的图,包含$dw$和$dh$。
此外改论文中指出通过这样的设计,它可以更好的捕捉更高或更宽的物体。
Anchor-Guided Feature Adaptation
传统的RPN网络中,由于每个位置的Anchor有相同的尺度和长宽比,因此特征图可以学习到一致性的表达,然而在GA-RPN中,Anchor的形状因位置而异。若是依然根据之前的方法,则违背了一致性原则。为此,引出了anchor-guided feature adaptation模块,该模块的公式化表达如下所示:
其中$f_i$是在$i$-th位置的特征,$(w_i,h_i)$是对应的anchor的形状。该分支首先通过一个$1\times1$的卷积从anchor shape预测分支输出一个offset field,接着运用可变卷积联合原始的特征图和offset field获得$f’_I$。后续的基于该adapted features进行分类与回归。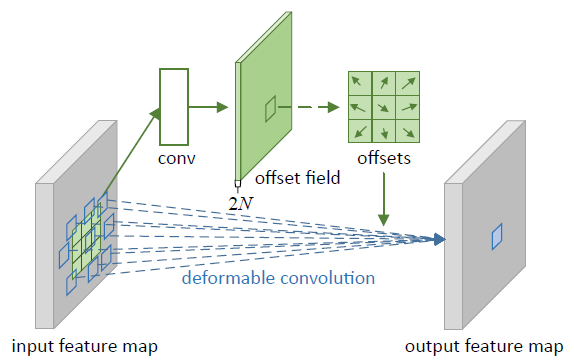
原始的可变卷积中,offset field是通过feature map来预测的,而该分支中的offset field是通过anchor shape来预测的,这也是为何称之为anchor-guided feature adaptation模块。
training
joint objective
anchor location targets
定义三个anchor location区域,CR(center region),IR(ignore region),OR(outside region)
CR是中心区域的周围区域,IR是中心区域外围的一部分区域,OR是除了CR和IR外面的所有区域。其中存在两个超参数,一个是CR的范围$\sigma_1$一个是IR的范围$\sigma_2$
由于CR占比较小,所以训练loss采用Focal loss.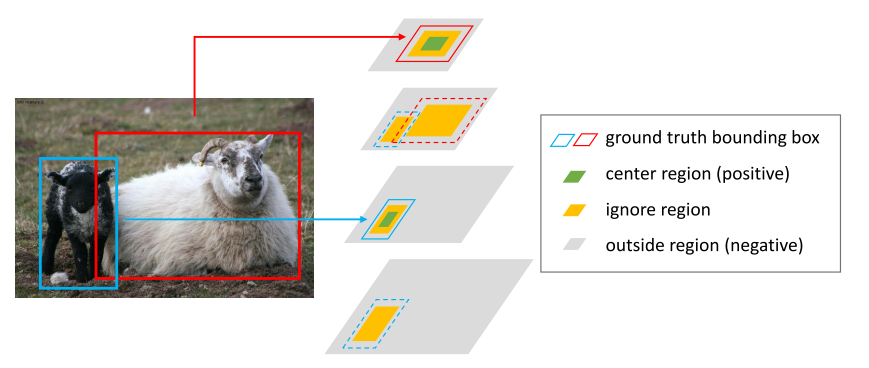
anchor shape targets
anchor形状的优化一般分为两步,首先将Anchor与对应的ground-truth bbox进行匹配,然后迭代的计算最优的$\hat{w}$和$\hat{h}$使其IoU最大化。之前的RPN网络分配一个候选的anchor给ground-truth bbox。但是对于GA-RPN则不适用,因为$w$和$h$并没有预定义。然后提出的解决措施是,基于$(x,y)$位置,采样9对不同尺度和长宽比的anchor。对于loss函数的优化采用的是bounded iou loss。
实验
超参数设置:$\sigma_1=0.2$,$\sigma_2=0.5$,$\lambda_1=1$,$\lambda_2=0.1$
与Fast_RCNN, Faster_RCNN, RetinaNet对比实验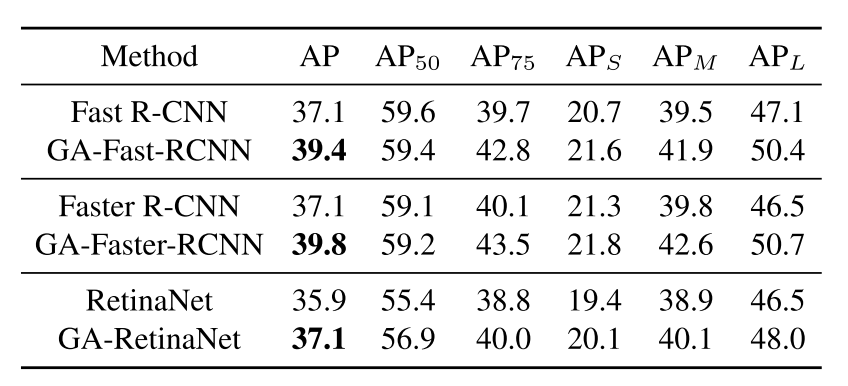
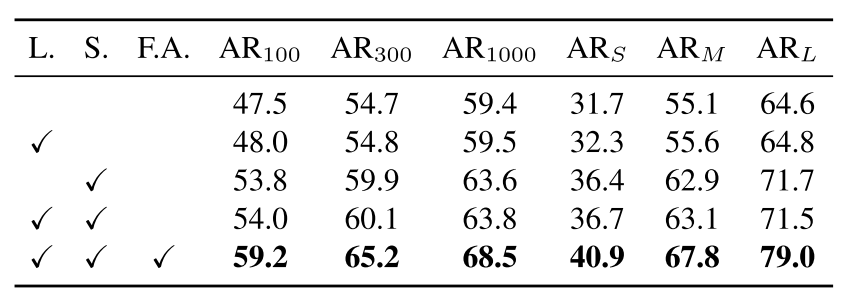
消融实验